1. Problemstellung
LLMs und Embedding-Modelle können keine unbegrenzt langen Dokumente verarbeiten, wie wir schon wissen und im vorherigen Punkt (Seite) erläutert haben.
Daher müssen Dokumente:
Die zentrale Herausforderung:
Wie groß darf ein Chunk sein, damit semantische Qualität erhalten bleibt, ohne Performance und Kontextfenster zu überlasten? Hier haben wir lange ausprobiert und bis heute wahrscheinlich noch nicht die optimale Lösung gefunden. Aber eine gute Lösung.
2. Warum Dokumente nicht als Ganzes verarbeitet werden können
Technische Gründe
-
Embedding-Modelle haben Token-Limits
-
LLMs haben Kontextfenster (z. B. 16k, 32k, 65k Tokens)
-
Große Texte verursachen:
3. Zielkonflikt beim Chunking
|
Große Chunks
|
Kleine Chunks
|
|
Mehr Kontext
|
Weniger Kontext
|
|
Bessere Kohärenz
|
Präzisere Retrieval-Treffer
|
|
Höherer Tokenverbrauch
|
Mehr Datenpunkte
|
|
Weniger Indexeinträge
|
Größerer Vektorindex
|
4. Konkrete Parameter bei unserem System
max_chars = 1400
overlap = 200
max_chars
overlap
Wir hatten bereits Längen von 400 bis 4.000 und einen Overlap von 50 bis 500.
Erst als wir die einzelnen vorhandenen Artikel beispielsweise gemäß der DSGVO aufteilten, um die Anker (siehe vorherige Seite) perfekt zu platzieren, konnten wir eine gute Einstellung der Parameter finden. Heute findet das System zu beinahe 95 % die richtigen Inhalte. Zu Beginn unseres Versuchs lag die Quote bei unter 30 %. Wir optimieren weiter und werden das Thema hoffentlich noch verbessern. Es ist bereits gut, aber noch nicht top. Der Mensch muss immer noch mitdenken :).
5. Warum Überlappung notwendig ist
Beispiel:
Chunk A: "...Art. 32 DSGVO verpflichtet ..."
Chunk B: "...zur Implementierung geeigneter Maßnahmen."
Semantischer Zusammenhang geht verloren.
Mit Overlap:
6. Herausforderungen bei juristischen Dokumenten
Juristische Texte haben besondere Eigenschaften:
Probleme:
-
Ein Normtext kann mehrere Absätze umfassen.
-
Definitionen stehen oft getrennt von der eigentlichen Verpflichtung.
-
Fußnoten und Erwägungsgründe beeinflussen Kontext.
7. Typische Fehlerszenarien
7.1 Chunk zu klein
-
Verlust juristischer Kohärenz
-
Pflicht und Ausnahme landen in verschiedenen Chunks
-
LLM erhält unvollständigen Kontext
Ergebnis:
-
Fragmentierte Antworten
-
Fehlinterpretationen
7.2 Chunk zu groß
-
Embedding wird „verwässert“
-
Mehrere Themen im selben Vektor
-
Retrieval verliert Präzision
Ergebnis:
7.3 Zu hoher Overlap
8. Mathematische Perspektive
Angenommen:
-
Dokument: 30.000 Zeichen
-
Chunkgröße: 1.500
-
Overlap: 200
Anzahl Chunks ≈
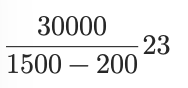
Jeder Chunk → eigener Vektor.
Bei 1.000 Dokumenten:
23.000 Vektoren
Indexgröße wächst linear mit Chunkanzahl.
9. Auswirkungen auf Retrieval
Retrieval-TopK
Wenn:
Dann:
10. Performance-Auswirkungen
Große Chunks:
Kleine Chunks:
11.
Zusammenfassung
Chunking ist kein technisches Detail, sondern:
ein entscheidender Qualitätsfaktor für RAG-Systeme.
Falsche Chunkgrößen führen zu:
Wichtig:
Wenn die Parameter geändert werden, muss die Vektordatenbank gelöscht und alle Dokumente neu vektorisiert werden.