1. Ziel der Vektorisierung
Ziel ist es, hochgeladene Dokumente so zu transformieren, dass:
Die Vektorisierung bildet Textabschnitte in numerische Vektoren im n-dimensionalen Raum ab.
Beispiel:
Ein Embedding-Modell nimmt einen Textabschnitt (Chunk) und erzeugt daraus eine Zahlenliste:
"Art. 32 DSGVO – Sicherheit der Verarbeitung"
wir zu: [0.0124, -0.9931, 0.4412, ..., -0.1177]
Diese Liste kann z. B. 768, 1024 oder 1536 Dimensionen haben.
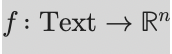
Das heißt:
1.1 Was repräsentieren diese Zahlen?
Die einzelnen Zahlen sind keine „Wörter“.
Sie kodieren:
-
semantische Beziehungen
-
syntaktische Strukturen
-
Kontext
-
thematische Nähe
-
implizite Bedeutungen
Wichtig:
Die Bedeutung entsteht nicht aus einer einzelnen Dimension,
sondern aus der relativen Position des gesamten Vektors im Raum.
1.2 Warum n-dimensional?
Weil Sprache hochkomplex ist.
Ein einzelnes Wort kann gleichzeitig:
-
juristisch sein
-
personenbezogen
-
normativ
-
verpflichtend
-
sicherheitsrelevant
-
europarechtlich
Diese semantischen Eigenschaften werden als unabhängige Richtungen im Raum modelliert.
Je mehr Dimensionen:
1. 3 Wie entsteht semantische Nähe?
Zwei Texte sind ähnlich, wenn ihre Vektoren „nah“ beieinander liegen.
Gemessen wird typischerweise mit:
Cosine Similarity (Definition des Systems)
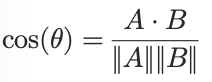
Beispiel:
Frage:
„Welche Pflichten bestehen bei Datenlöschung?“
Treffer:
„Recht auf Löschung nach Art. 17 DSGVO“
Auch wenn „Pflichten“ ≠ „Recht“, erkennt das Modell semantische Nähe
1.4 Unterschied zu klassischer Volltextsuche
Volltext
Problem:
Vektorsuche
-
basiert auf Bedeutungsnähe
-
funktioniert bei Umformulierungen
-
erkennt konzeptuelle Zusammenhänge
Beispiel:
„technische und organisatorische Maßnahmen“≈„Sicherheitsvorkehrungen nach Art. 32 DSGVO“
1.5 Warum Chunking vor der Vektorisierung?
Ein komplettes Gesetz als ein Vektor wäre:
-
zu grob
-
kontextuell ungenau
-
Retrieval unpräzise
Durch Chunking:
Beispiel:
angenommen:
Dann speichere ich:
300 x 1024 Werte
Das ist eine Matrix:
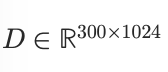
Bei einer Anfrage:
1.6 Warum diese Methode für juristische Dokumente sinnvoll ist
Juristische Sprache:
-
enthält Synonyme
-
implizite Verweise
-
systematische Struktur
Beispiel:
Art. 32 DSGVO spricht von:
-
„Vertraulichkeit“
-
„Integrität“
-
„Belastbarkeit“
Eine Frage nach „Zugriffskontrolle“ wird trotzdem korrekt gematcht.
Das ist mit Keyword-Suche kaum möglich.
2. Sicherheit von Emeddings
Embeddings sind:
-
numerische Repräsentationen von Text
-
hochdimensionale Vektoren
-
nicht direkt menschenlesbar
-
aber informationshaltig
Wichtig:
Ein Embedding ist keine Anonymisierung, sondern eine Transformation.
2.1 Welche Informationen enthalten Embeddings?
Embeddings kodieren:
-
semantische Struktur
-
kontextuelle Bedeutung
-
thematische Nähe
-
implizite Zusammenhänge
Nicht enthalten sind:
Aber:
Sie enthalten genügend Information, um:
2.2 Risikoanalyse
Theoretisch möglich:
Realistisch betrachtet:
-
Vollständige Rekonstruktion ist extrem schwierig
-
Besonders bei modernen Embedding-Modellen
-
Aber Teilinformationen können inferiert werden
3. Zusammenfassung
Die Vektorisierung wandelt Textabschnitte in hochdimensionale numerische Repräsentationen um, die die semantische Bedeutung kodieren.
Mithilfe dieser Repräsentationen ist eine bedeutungsbasierte Ähnlichkeitssuche mittels Cosine Similarity möglich.
Dadurch wird eine robuste juristische Dokumentensuche ermöglicht, die auch bei Paraphrasen und konzeptuellen Umformulierungen zuverlässig funktioniert.
Allerdings wächst die Vektorendatenbank schnell an. Bei mir wird eine SQLite-DB verwendet. Allein die Vektorisierung der DSGVO, des BDSG, des TDDDSG und einiger Richtlinien benötigt etwa 18 GB.
Außerdem musste ich mit Metadaten arbeiten, damit Paragrafen und Artikel ordnungsgemäß erkannt werden und die Priorisierung der Gesetze und Richtlinien korrekt erfolgt. Ich habe dazu Anker gesetzt, die die Gewichtung vorab beeinflussen. Damit das funktioniert, habe ich Folgendes eingeführt: Die Anker werden aus dem Titel der Dokumente gewonnen.
Beispiel:
Dateiname-Regeln (wichtig für Doctype/Issuer/Normen)
Empfohlenes Schema (mit Jahr):
<doctype>_<issuer>_<docref>_<topic>_<year>_<title>.pdf
Alternatives Schema (ohne Jahr):
<doctype>_<issuer>_<docref>_<topic>_<title>.pdf
doctype: gesetz, urteil, leitlinie, richtlinie, vorlage
Wird intern normalisiert zu: law, case, guideline, policy_internal, template.
Beispiele:
gesetz_EU_DSGVO_datenschutz_2016_Art-13-DSGVO-Informationspflichten.pdfgesetz_DE_BDSG_datenschutz_2019_Para-26-BDSG-Beschaeftigtendaten.pdfleitlinie_DSK_Orientierungshilfe_datenschutz_2022_TOMs-und-Art-32.pdfurteil_EU_EuGH_datenschutz_2023_Auskunft-und-Kopie.pdfrichtlinie_INTERNAL_Loeschkonzept_datenschutz_2024_Loeschkonzept-v1.pdf
Tipp: Für Normanker nutze im title am Anfang Art-XX oder Para-XX, damit anchor_key sauber erkannt wird.
3.1 Zur Sicherheit und Datenschutz.
Die Datenbank muss gut geschützt sein, da es datenschutzrechtliche Bedenken gibt (siehe Punkt 2). Das ist ein Grund, keine KI eines Drittherstellers für ein RAG-System zu verwenden. Des Weiteren muss ein entsprechender Zugriffsschutz vorhanden sein. Es bleibt die Frage, ob man ein KI System auch dazu motivieren kann eine Auswertung der Datenbank vorzunehmen (Prompt-Injection).